Modely databázových systémov
Najrozšírenejšie modely databáz
Sieťový model
Sieťový model databáz vznikol zhruba v rovnakej dobe, ako hierarchický model. Najrozšírenejšou databázou postavenou na sieťovom modeli bol systém IDMS (Integrated Database Management System), ktorý pôvodne vyvinula spoločnosť Cullinane (neskôr Cullinet). Produkt bol ďalej zdokonaľovaný a doplnený o relačné rozšírenie, bol premenovaný na IDMS/R a nakoniec bol predaný spoločnosti Computer Associates.
To, čo v systéme s otvorenými súbormi ukladáme do samostatných súborov, definujeme v hierarchickom modeli ako typy záznamov (alebo jednoducho “záznamy”), pričom jednotlivé záznamy spájame reláciami jedna k viacerým, ktorým sa v terminológii sieťového modelu hovorí relácia vlastník - člen alebo množiny . My ale opäť pre jednoduchosť zostaneme pri klasickejších pojmoch rodič a potomok. Rovnako ako v hierarchickom modeli sa i tu podobné záznamy prepájajú pomocou ukazovateľov s fyzickými adresami. Taktiež identifikácia rodičovských záznamov je z potomkov vypustená, aby nedochádzalo k nekonzistenciám v dátach. Na rozdiel hierarchického modelu sú v tomto prípade vzťahy alebo relácie medzi dátami pomenované, tak že programátor môže v databáze prikázať prechod z jedného záznamu na iný prostredníctvom konkrétnej relácie a jeden typ záznamov sa tak fakticky môže na strane potomka zúčastniť na niekoľkých reláciách.
Ďalšia manipulácia s dátami : prechod na záznam s danou hodnotou pola, nastavenie na prvý členský záznam, na ďalší záznam, vytvorenie, zrušenie, modifikácia záznamov, zapojenie, vyradenia, prepojenie z väzby.
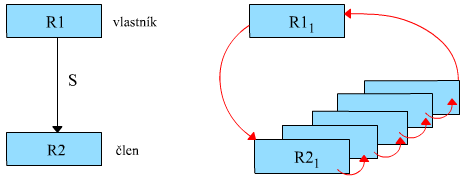
Sieťový model znamenal vyššiu flexibilitu, ale podobne, ako je tomu pri počítačových systémoch celkom často, bolo to za cenu vyššej zložitosti .
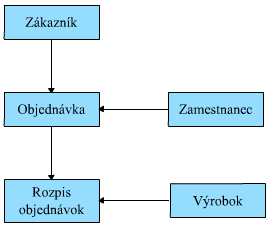
Obrázok 1.5: Štruktúra sieťového modelu databázy
Taktiež do sieťového modelu si teraz na ukážku prevedieme časť štruktúry databázy zo systému otvorených súbor. Ako vidíme z obrázku 1.5, sú tu rovnaké záznamy, ako v ekvivalentnej štruktúre hierarchického modelu z obrázku 1.3. Šípky na spojovacích čiarach vedú podľa konvencie z rodičovského záznamu k potomkovi. Všimnite si, že v tomto diagrame sú už záznamy Zákazník a Zamestnanec prepojené plnou čiarou, pretože príslušnú reláciu môžeme implementovať priamo.
Na obrázku 1.6 vidíme opäť obsah databázy podľa sieťového modelu. V tomto prípade je každý typ relácie rodič - potomok znázornený iným typom čiary a indikuje to iný názov relácie. Tento rozdiel je veľmi dôležitý, pretože z neho vidíme najväčšiu nevýhodu sieťového modelu – a tou je jeho zložitosť . Namiesto jednej cesty sa spracovanie záznamu sa môže riadiť podľa niekoľkých rôznych ciest. Ak napríklad začneme pri zázname zamestnanca číslo 4 (obchodný zástupca Klinček Peter) a vyhľadáme podľa neho prvú dohodnutú objednávku (číslo 10692), dostaneme sa naraz do stredu celého reťazca objednávok, ktoré patria zákazníkovi ALFKI. Aby sme teraz mohli nájsť všetky ostatné objednávky rovnakého zákazníka, musíme sa nejakým spôsobom prepracovať z aktuálneho miesta na koniec reťazca a potom preskočiť na začiatok a odtiaľ postupovať späť k aktuálnej objednávke. Popísané spracovanie sieťového modelu môže pracovať len za podmienky, že všetky reťazce ukazovateľov v databáze sú kruhové (cyklické). A ako si iste viete sami predstaviť, pokiaľ užívateľ databázy nebude tieto kruhové reťazce pozorne “strážiť”, môžu z nich veľmi ľahko vzniknúť nekonečné slučky (teda proces, ktorý nikdy neskončí). Veľmi voľnou paralelou k sieťovej štruktúre databáz je napríklad štruktúra stránok v sieti World Wide Web, preto že prakticky každá webová stránka obsahuje odkazy na iné, príbuzné webové stránky a nie sú vôbec neobvyklé kruhové reťazce odkazov.
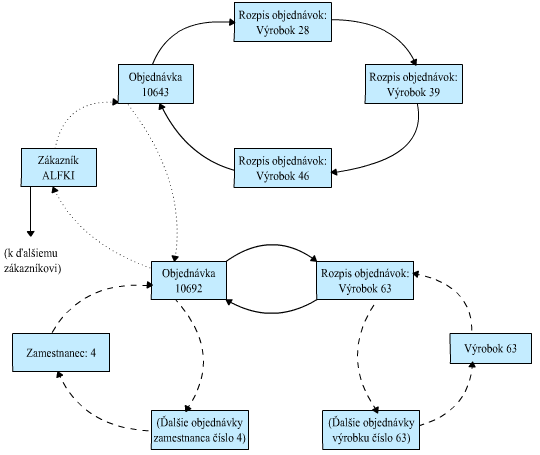
Obrázok 1.6: Obsah záznamov v sieťovom modeli databázy
Proces navigácie v sieťovej databáze býval nazývaný “prechádzanie množinami”, pretože jeho súčasťou je výber ciest v databázovej štruktúre – a ten sa podobá napríklad chodeniu po lese, kde sa do rovnakého cieľa môžeme taktiež dostať po viacerých rôznych cestách. Bez aktuálnej “turistickej” mapy veľmi ľahko zablúdime, alebo ešte horšie, natrafíme napríklad na slepú uličku, z ktorej sa do cieľa, teda cieľového záznamu nedostaneme vôbec. Obrovská zložitosť a nutnosť nákladného udržovania databázy viedla k zániku tohto modelu.
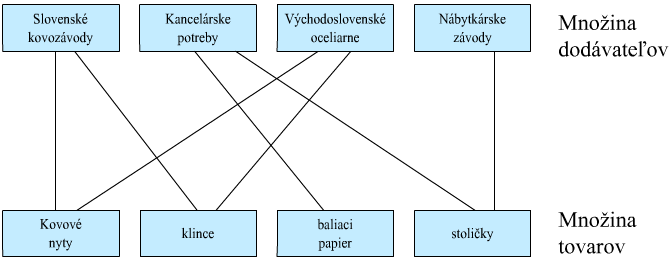
Obrázok: Jednoduchý model sieťového databázového systému: Podnik XY, s.r.o.