Vrstvy dátovej abstrakcie
| Portál: | E-learningový vzdelávací portál Slovenskej poľnohospodárskej univerzity v Nitre |
| Kurz: | Databázové systémy |
| Kniha: | Vrstvy dátovej abstrakcie |
| Vytlačil(a): | Hosťovský používateľ |
| Dátum: | nedeľa, 28 decembra 2025, 16:01 |
Opis
Vrstvy dátovej abstrakcie
Vrstvy dátovej abstrakcie
Databázy majú jedinečnú schopnosť ponúknuť rôznym užívateľom, na jednak rovnaké a jednak iba jeden krát uložené podkladové dáta rôzne, samostatné pohľady na tieto rovnaké dáta. Abstraktný pohľad na dáta - sú skryté detaily uloženia a správy dát:

Týmto pohľadom sa jednoducho hovorí užívateľské pohľady. Za užívateľov môžeme v tejto súvislosti považovať ľubovoľnú osobu alebo aplikáciu, ktorá sa môže prihlásiť do databázy za účelom uloženia alebo načítania dát. Aplikácia je pritom množina počítačových programov určených na riešenie určitého vecného problému. Príkladom aplikácie môže byť napríklad systém pre vybavovanie objednávok, pre spracovanie platov alebo vedenie účtovníctva.
V prípade, že určité dáta uložíme do elektronickej tabuľkovej aplikácie, ako je napr. MS Excel, musia všetci užívatelia pracovať s jedným spoločným pohľadom a tento pohľad sa musí zhodovať so spôsobom fyzického uloženia dát v podkladovom dátovom súbore. Pokiaľ jeden užívateľ v tabuľkovom liste skryje niekoľko stĺpcov alebo zmení usporiadanie riadkov a potom zošit uloží, bude mať ďalší užívateľ pred sebou požadované dáta v presne takej podobe, v akej ich prvý užívateľ uložil. Alternatívou, samozrejme, je, že si každý z užívateľov uloží dáta v samostatnej kópii do iného fyzického súboru, ale akonáhle uskutoční jeden užívateľ zmeny vo svojej kópii údajov, druhý užívateľ už nemá k dispozícii ich aktuálnu podobu.
V databázovom systéme môžeme – na rozdiel od spomínaného prístupu – každému jednotlivému užívateľovi ponúknuť iný pohľad na rovnaké dáta, pričom tieto pohľady môžu byť každému z nich „ušité na mieru“, pretože pracujú nad jednou spoločne uloženou kópiou dát. Pretože v pohľadoch nie sú uložené žiadne skutočné dáta, odrážajú sa v nich automaticky akékoľvek zmeny uskutočnené v podkladových databázových objektoch. To je možné vďaka tzv. vrstvám abstrakcie, ktoré zachytáva nasledujúci obrázok:
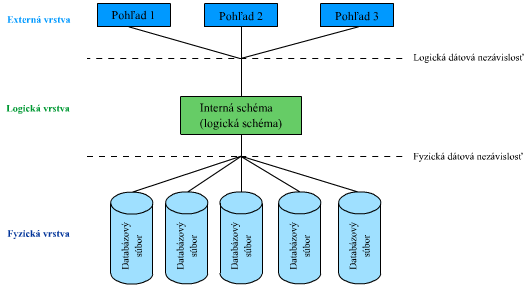
Architektúra, ktorá je znázornená na predchádzajúcom obrázku a navrhnutá v sedemdesiatych rokoch výborom SPARC (Standards Planning and Requirements Committee) amerického ANSI (American National Standards Institute), sa rýchlo stala základom veľkej časti ďalších výskumných a vývojových prác v oblasti databáz. Je na nej postavená taktiež väčšina moderných databázových systémov, pričom sa skladá z 3 základných vrstiev:
- externá (aplikačná) vrstva – (úroveň pohľadov) – opisuje, aké dáta vidia jednotliví užívatelia, t.j. časť databázy, ktorú predstavujú dáta reprezentujúce objekty reálneho sveta, viditeľné jednotlivými užívateľmi diferencovanými z dôvodu odborného zamerania, prístupových práv a podobne;
- logická vrstva (konceptuálna - logická úroveň) – opisuje, aké dáta sú skutočne uložené v databáze a aké vzťahy medzi nimi existujú;
- fyzická vrstva – (fyzická úroveň) – opisuje dáta tak, ako sú skutočne uložené.
Trojúrovňová architektúra (ANSI/SPARC) – 70-te roky, snaha o štandardizáciu:

Obrázok: Schéma - externá, konceptuálna, dátová, fyzická
Fyzická vrstva
Fyzická vrstva obsahuje dátové súbory, do ktorých sa ukladajú akékoľvek dáta príslušnej databázy. Podľa konkrétneho databázového systému môže byť pritom jedna databáza uložená v niekoľkých dátových súboroch, umiestnených často na fyzicky rôznych diskových jednotkách (napr. Oracle). Pri tomto usporiadaní môžu všetky diskové jednotky pracovať súbežne, a databáza tak dosiahne vyšší výkon.
Jednou z výnimiek je MS Access, pod ktorým sa celá databáza ukladá do jedného fyzického súboru (*.accdb). Toto usporiadanie však znamená obmedzenie možnosti škálovania databázového systému, ktorý sa nedokáže prispôsobiť väčšiemu počtu súčasne pracujúcich užívateľov a ktorý tak nie je vhodným riešením pre veľké podnikové systémy. Na druhej strane sa tým ale zjednodušuje práca s databázou na osobnom počítači konkrétneho užívateľa.
Užívateľ databázy vôbec nemusí vedieť, akým spôsobom sú dáta v dátových súboroch uložené, ba dokonca nemusí vedieť, v ktorom fyzickom súbore sa ním požadované dátové položky nachádzajú. To je vo väčšine organizácií vecou špecializovaného správcu alebo databázového administrátora, ktorý má na starosti akúkoľvek inštaláciu a konfiguráciu databázového softvéru a dátových súborov a povoľuje užívateľom prístup k databáze. Databázový systém potom v spolupráci s operačným systémom počítača automaticky zaisťuje správu dátových súborov, do ktorých patrí akékoľvek otváranie a zatváranie súborov a operácie čítania a zápisu údajov. Systém by od užívateľa pri práci s databázou nemal vyžadovať zadávanie názvov konkrétnych fyzických súborov, čo je v priamom kontraste s tabuľkovými a textovými aplikáciami, kde užívateľ – naopak – musí výslovne uložiť dokument a zvoliť preň konkrétny názov a umiestnenie.
Viaceré z databázových systémov, určených pre osobné počítače, sú výnimkou z tohto pravidla, pretože užívateľ musí pri prihlasovaní sa k databáze vyhľadať a otvoriť ich fyzický súbor. Serverovo orientované databázové systémy, akým je Oracle, Sybase, Microsoft SQL Server a ďalšie, zaisťujú však správu fyzických súborov automaticky a užívateľ sa na ne pri práci s databázou nemusí vyslovene odvolávať.
Logická vrstva
Logická vrstva alebo – inak povedané – logický model predstavuje prvú z dvoch vrstiev abstrakcie v databáze. Je to tak preto, že fyzická vrstva skutočne existuje a je realizovaná v konkrétnych súboroch operačného systému, zatiaľ čo logická vrstva je iba súčasťou abstraktných dátových štruktúr, ktoré sa podľa potreby skladajú z objektov fyzickej vrstvy. Táto logická vrstva sa niekedy označuje pojmom logická schéma a opisuje typy objektov databázy, ich štruktúru a vzťahy medzi nimi.
Existuje viacero rôznych spôsobov tvorby logických schém, čiže modelovania databázovej štruktúry. Tieto sa nazývajú databázovými modelmi (alebo modelmi dát). Podľa konkrétneho databázového systému môže byť logická schéma tvorená množinou dvojrozmerných tabuliek, hierarchickou štruktúrou, podobnou napríklad organizačným diagramom firmy, alebo inou štruktúrou. Používané databázové štruktúry opisujeme na inom mieste, v časti „Najrozšírenejšie modely databáz“.
Na úrovni logickej schémy databázy sa pracuje s pojmami:
- typ objektu,
- vlastnosť objektu,
- vzťahy medzi typmi objektov.
Táto logická schéma databázy sa mení len zriedkavo, častejšie sa menia počty inštancií objektov a aj inštancie vzťahov medzi konkrétnymi objektmi.
Príklad:
Typ objektu: učiteľ, predmety, miestnosti, ...
Vlastnosti objektov: rodné číslo, meno, priezvisko, ...
Vzťahy: učiteľ – predmet.
Schéma databázy je len opis a existuje už aj vtedy, keď do nej nie je priradený žiadny objekt. Vloženie konkrétneho objektu sa nazýva inštancia.
Externá vrstva
Externá vrstva alebo – inak povedané – externý model je druhou z vrstiev abstrakcie v databáze. Túto vrstvu tvoria užívateľské pohľady, ktoré sa súhrnne nazývajú subschéma – je reprezentovaná dátami z pohľadu užívateľa (subschéma je určitá časť schémy).
V tejto vrstve sa k databáze pripájajú užívatelia a aplikačné programy, ktoré s ňou ďalej pracujú, t.j. zadávajú a vytvárajú v nej dopyty. Externú vrstvu môžu predstavovať napr. výstupné tlačové zostavy, formuláre pre vstup dát, poprípade iné dáta, ktoré obsahujú informáciu užitočnú pre užívateľov informačného systému. Rôzny užívatelia môžu "vidieť" (z dôvodu odborného zamerania, prístupových práv a pod.) rôzne vymedzené časti informačného obsahu databázy. Preto všeobecne platí, že subschém je toľko, koľko je užívateľov.
Do priameho styku s fyzickou a logickou vrstvou vstupuje v ideálnom prípade len databázový administrátor. Databázový systém potom zaisťuje transformáciu vybraných položiek z jednej alebo viacerých dátových štruktúr v logickej vrstve do konkrétneho užívateľského pohľadu. Pretože sa užívateľské pohľady vytvárajú v tejto externej vrstve, môžu byť dopredu definované a uložené do databázy, kde ich ktokoľvek môže znovu využiť alebo môžu byť vytvorené len ako dočasné položky, v ktorých si databázový systém ukladá výsledky jednorázového dopytu. Výrazom jednorázový alebo ad hoc dopyt myslíme taký dopyt, ktorý nebol zostavený dopredu a ktorý zrejme nebude znovu využívaný.
Nezávislosť dát
Nezávislosťou dát sa v databázových systémoch rozumie možnosť zmeniť definíciu dát na nižšej úrovni abstrakcie bez ovplyvnenia definície na vyššej úrovni abstrakcie. Hovoríme o dvoch úrovniach nezávislosti dát.
Fyzická dátová nezávislosť
Možnosť zmeny fyzickej súborovej štruktúry v databáze bez narušenia logickej schémy a činnosti nasledujúcich užívateľských aplikačných programov a procesov sa označuje ako fyzická dátová nezávislosť alebo nezávislosť dát na ich fyzickom uložení.
Fyzická dátová nezávislosť je v databázovom systéme práve vďaka oddeleniu fyzickej vrstvy od logickej. Na tomto mieste je dôležité povedať, že fyzická dátová nezávislosť nie je vlastnosť, ktorú „buď máme alebo nemáme“, ale ktorá sa môže pohybovať na určitej škále – v jednom databázovom systéme sú dáta viac fyzicky nezávislé ako v inom databázovom systéme. Meradlo, resp. stupeň fyzickej dátovej nezávislosti vyjadruje, aké zmeny môžeme previesť vo fyzickom súborovom systéme bez zásahu do logickej vrstvy.
Pred vznikom databázového systému s fyzickou dátovou nezávislosťou totiž i najmenšia zmena v spôsobe uloženia dát znamenala veľké zmeny v aplikáciách – do všetkých programov, ktoré s týmito dátami pracovali, museli zasahovať celé štáby programátorov – tento proces bol veľmi nákladný a časovo náročný.
Určitý stupeň fyzickej dátovej nezávislosti je súčasťou všetkých moderných počítačových systémov. Tabuľkový zošit v MS Excel na osobnom počítači bude napríklad pracovať rovnako dobre, aj keď ho z pevného disku skopírujeme na prenosný USB disk či napálime na CD. Pri týchto zariadeniach sa výrazne líši nielen rýchlosť prístupu k údajom, ktorá nie je príliš podstatná, ale najmä ich celá fyzická konštrukcia – operačný systém na osobnom počítači zvládne napriek tomu i tieto rozdiely a načítané údaje predloží cieľovej aplikácii (tu momentálne tabuľkovému procesoru MS Excel) i samotnému užívateľovi presne rovnakým spôsobom. Na väčšine osobných systémov si musí užívateľ pamätať, kam súbor uložil, aby ho v prípade potreby dokázal znovu nájsť.
Databázové systémy idú v otázke fyzickej dátovej nezávislosti na počítačovom systéme omnoho ďalej: akýkoľvek užívateľ databázy môže pracovať s databázovými objektmi (napr. s tabuľkami v relačnej databáze) i bez znalostí fyzického umiestnenia dátových súborov a bez ich zadávania. Miesta fyzického uloženia týchto objektov si databázový systém sleduje v tzv. katalógoch.
Pozrime sa teraz na niekoľko príkladov fyzických zmien, ktoré sa dajú realizovať dátovo nezávislým spôsobom:
- presunutie dátového súboru databázy z jedného zariadenia do iného alebo z jedného adresára do iného,
- rozdelenie alebo zlúčenie dátových súborov databázy,
- premenovanie databázových súborov,
- premiestenie databázového objektu z jedného súboru do druhého,
- pridanie nových databázových objektov alebo dátových súborov.
Všimnite si, že sme vôbec nehovorili o odstraňovaní objektov alebo položiek. Určite i vám je na prvý pohľad jasné, že po odstránení objektov prestane fungovať všetko, čo s týmto objektom donedávna pracovalo. Všetko ostatné by ale malo pracovať i naďalej správne.
Logická dátová nezávislosť
Možnosť realizovania zmien v logickej vrstve bez narušenia činnosti nasledujúcich užívateľských aplikačných programov a procesov označujeme ako logická dátová nezávislosť alebo nezávislosť dát na logickej štruktúre.
Z predchádzajúceho obrázku je možné vidieť, že za logickou dátovou nezávislosťou stojí transformácia medzi logickou vrstvou a externou vrstvou. Podobne ako pri fyzickej dátovej nezávislosti, existujú rôzne stupne i pri logickej dátovej nezávislosti.
Je dôležité si uvedomiť, že väčšina logických zmien so sebou prináša taktiež určitú fyzickú zmenu. Do databázy napríklad ťažko môžeme pridať nový databázový objekt (napr. tabuľku v relačnom databázovom systéme) bez toho, aby sme jeho dáta niekam uložili – to skutočne znamená zodpovedajúcu zmenu vo fyzickej vrstve. A taktiež po odstránení objektu z logickej vrstvy prestane fungovať všetko, čo s ním dovtedy pracovalo – ostatné časti systému zostanú ale nedotknuté.
Tu je niekoľko príkladov zmien v logickej vrstve, ktoré môžeme v databáze realizovať práve vďaka logickej dátovej nezávislosti:
- pridanie nového databázového objektu,
- pridanie dátových položiek (vlastností) k jednotlivým objektom bez toho, aby to ovplyvnilo pôvodné aplikačné programy,
- akákoľvek zmena, pri ktorej môžeme pôvodný objekt logickej vrstvy nahradiť pomocou nového pohľadu v externej vrstve a naďalej s ním pracovať rovnako ako s pôvodným objektom – ide napríklad o zlučovanie a delenie objektov v databáze.