Modely databázových systémov
Modely databázových systémov
Najrozšírenejšie modely databáz
Relačný model
Hierarchický a sieťový model sú nie len zložité , na viac majú spoločnú ešte jednu nepríjemnú vlastnosť – sú veľmi nepružné, t.j. málo flexibilné. Efektívne spracovanie údajov je možné iba pri ich prechode po dopredu definovanej ceste. Pri jednorázových dotazoch, akými sú napr. vyhľadanie všetkých objednávok dodaných v určitom mesiaci, je nutné prehľadať celú databázu. Počítačový vedci hľadali preto ešte lepšie riešenie. V histórii vývoja počítačov bolo len málo okamžikov, ktoré sa dajú označiť za revolučný zlom, a jedným z nich bola i výskumná práca Dr. E.F. Codda, na základe ktorej sa zrodil relačný model databáz.
Relačný model databáz je postavený na myšlienke, že mať v dátovej štruktúre len jednu dopredu definovanú cestu je príliš obmedzujúce riešenie , najmä vo svete neustále rastúcich požiadaviek na podporu náhodných či jednorázovo požadovaných informácií. Užívatelia proste nemôžu myslieť na všetky možné spôsoby využitia dát v databáze dopredu, teda ešte pred jej vytvorením. Preto, pokiaľ pre spracovanie dát v databáze vyžadujeme len dopredu definované cesty, vytvoríme tím iba akési „dátové väzenie“. V relačnom modely máme preto možnosť zviazať záznamy len podľa potreby a nie podľa väzieb definovaných dopredu pri prvotnom ukladaní záznamov do databázy. Relačný model je na viac postavený takým spôsobom, že dotazy pracujú vždy s určitou množinou dát (napríklad so všetkými zákazníkmi, u ktorých máme nezaplatené pohľadávky), a nie s jednotlivými záznamami (ako celku ) , ako tomu bolo u sieťového a hierarchického modelu.
V relačnom modeli sú údaje reprezentované pomocou dvojrozmerných tabuliek ( usporiadané n-tice - prvky takýchto množín sa znázorňujú ako riadky tabuľky ) podobne ako predstavuje list tabuľkového editoru MS Excel. Na rozdiel od tabuľkového listu nemusia byť ale dáta nutne uložené v tabuľkovej podobe a model na viac povoľuje zlučovanie (v relačnej terminológii spájanie, JOIN) tabuliek do pohľadov, ktoré majú taktiež podobu dvojrozmerných tabuliek .
Skrátka a dobre, tento model zodpovedá architektúre ANSI/SPARC, a obsahuje teda slušnú dávku fyzickej a logickej dátovej nezávislosti. Namiesto prepájania príbuzných záznamov pomocou ukazovateľov s fyzickou adresou, ako tomu bolo v hierarchickom a v sieťovom modeli, sa v tomto prípade do každej z tabuliek zapíše určitá spoločná dátová položka , podobne ako pri systéme s otvorenými súbormi. Spoločné stĺpce tabuliek vytvárajú relácie medzi jednotlivými tabuľkami , názvy nemusia byť rovnaké, ale musia mať rovnakú doménu, typ, veľkosť.
Relatívnou nevýhodou relačných databáz je skutočnosť, že informácie sú rozptýlené po tabuľkách a pri rozsiahlejších dotazoch je potrebné informácie z tabuliek spájať.
Ukážka návrhu databázy v relačnom modeli je znázornená na nasledujúcom obrázku.
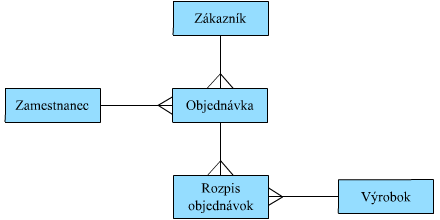
Obrázok 1.7: Ukážka štruktúry relačného modelu databázy
Ak sa pozrieme teraz späť na obrázok s otvorenými súbormi, jasne vidíme, že v tomto prípade sa všetky jednotlivé súbory zo systému otvorených súborov zmenili do podoby tabuliek (takáto jednoznačná korešpondencia medzi otvorenými súbormi a relačnými tabuľkami nemusí platiť úplne vždy, ale je napriek tomu skutočne veľmi bežná). Čiary medzi tabuľkami vyjadrujú vzťahy, alebo relácie typu jedna k viacerým, pričom ich koniec s jednou čiarkou zodpovedá vždy strene “jedna” a druhý koniec v tvare vidličky definuje stranu “viacej”. Z čiar na obrázku je napríklad vidieť, že “jeden” zákazník je zviazaný s “viacerými” objednávkami, a že k “jednej” objednávke patrí “viac” riadkov s rozpísanými informáciami z Rozpisu objednávok. Toto schematické znázornenie je označované ako diagramy entin a vzťahov alebo diagramy ER (z anglického Entiny-Relationship Diagram).
Na nasledujúcom obrázku sme z 5 tabuliek relačného modelu z obrázku 1.7 zvolili celkom 3 a v nich sme vybrali istú vzorku údajov. Ak sa pozrieme na stĺpec s identifikáciou zákazníka (Kód zákazníka), ten je zapísaný v tabuľke Zákazníci aj v tabuľke Objednávky. V prípade, že sa číslo v poli Kód zákazníka v riadku tabuľky Objednávky zhoduje s číslom zákazníka zapísaným v tabuľke Zákazníci, znamená to, že sme našli zákazníka, ktorému patrí táto konkrétna objednávka. Podobne je na tom aj stĺpec Číslo zamestnanca v tabuľke Zamestnanci a Objednávky a popisuje tak zamestnanca, ktorý objednávku od zákazníka prijal a vybavil v systéme.
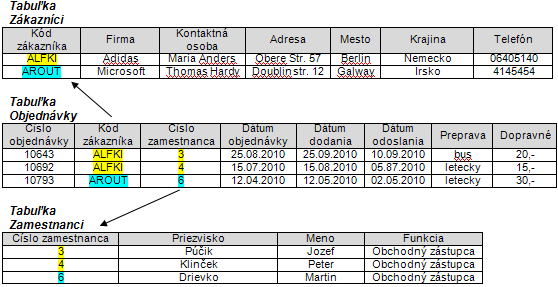
Obrázok 1.8: Obsah tabuliek v relačnom modely databázy
Veľkým prínosom relačného modelu je tiež fakt, že kladie dôraz na zachovanie integrity spracovávaných dát.
Najmä vďaka svojej elegantnej jednoduchosti a ľahkej zrozumiteľnosti bol relačný model nakoniec veľmi široko prijatý. Na tomto modeli je dnes založená drvivá väčšina komerčných databázových systémov (IBM DB2, Oracle - v súčasnosti majú oba zhruba tretinový podiel na databázovom trhu), MS SQL Server - v súčasnosti majú asi šestinu podielu na trhu, Sybase, Informix, PostgreSQL, Ingres, MySQL, MS Access, FoxPro, ....).